How to configure an AI Assistant for your website.
Effortlessly create AI assistants to enhance your website navigation, answer frequently asked questions, and provide smart access to resources like support guides, product catalogs. The AI assistant will be fully customizable and easily embedded on your website or internal applications with a simple HTML snippet.
1
Configure the Data Capture job
Specify the website URL or sitemap.
Begin by setting up a data capture job to “Retrieve Contents from Website.” This will crawl your
website and store data for use by AI assistants. Simply provide the website
URL;
Check the Page Limits setting, to set some boundaries to the number of pages
being stored. Additionally, you can also specify a sitemap with all URLs to crawl.
Run the job
Execute the web crawling job, and wait for it to be fully completed. It may take some time for all pages to be processed, specially if several prompts have been configured.
2
View the retrieved contents in the dataset
Crawled contents are stored and indexed in a dataset, which is a collection of contents that can be retrieved in multiple formats. It's important the crawled contents are relevant and have good quality to ensure the best replies from your assistants. You can also download them in JSON or CSV format.
3
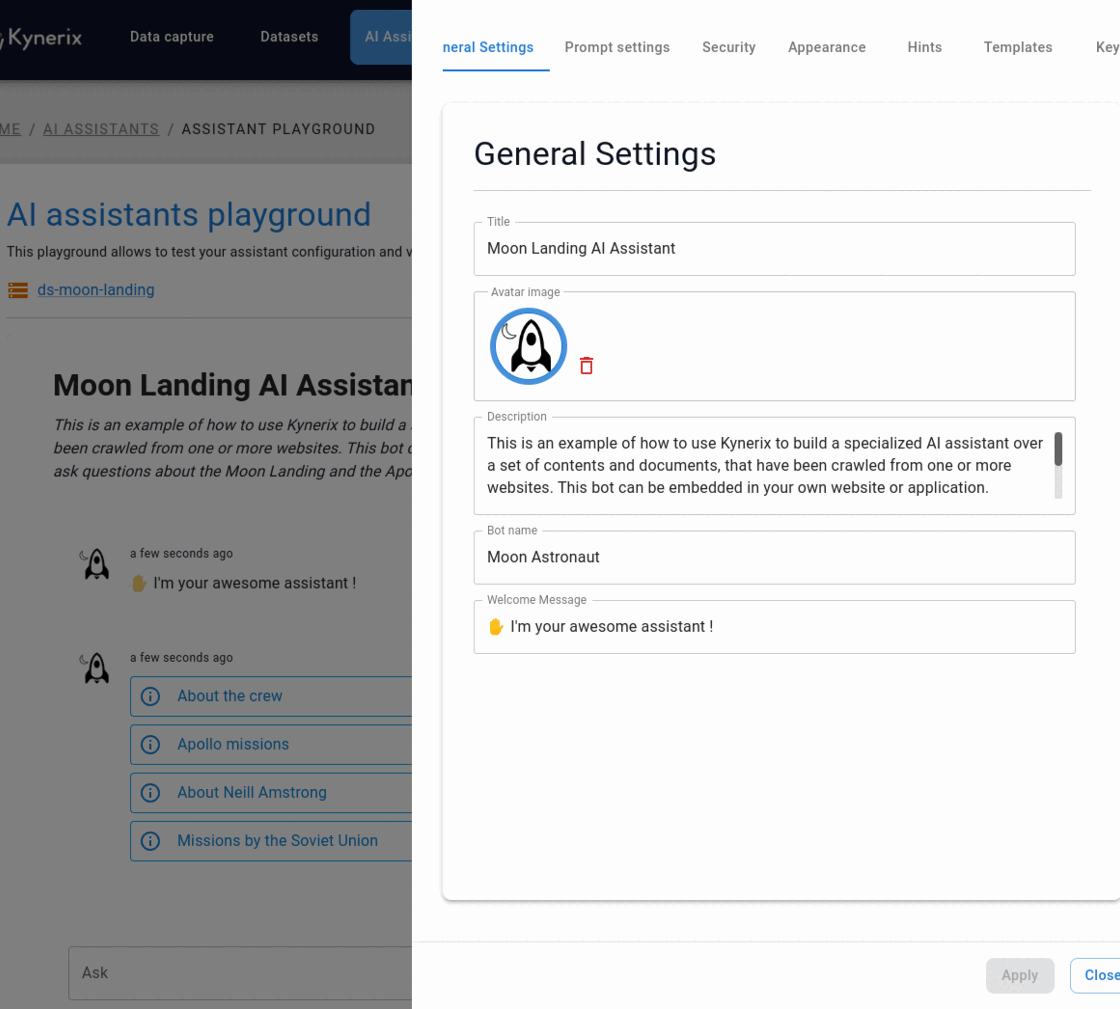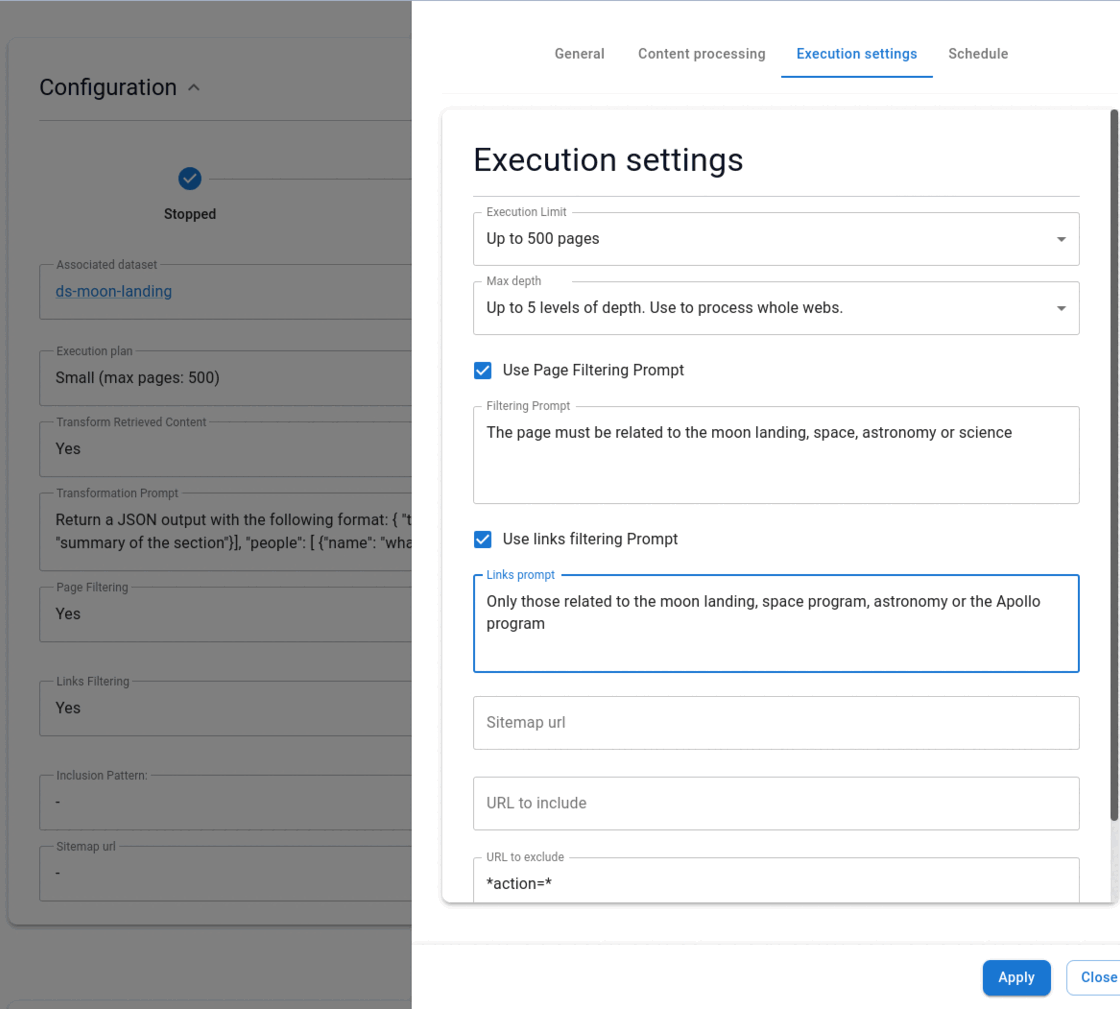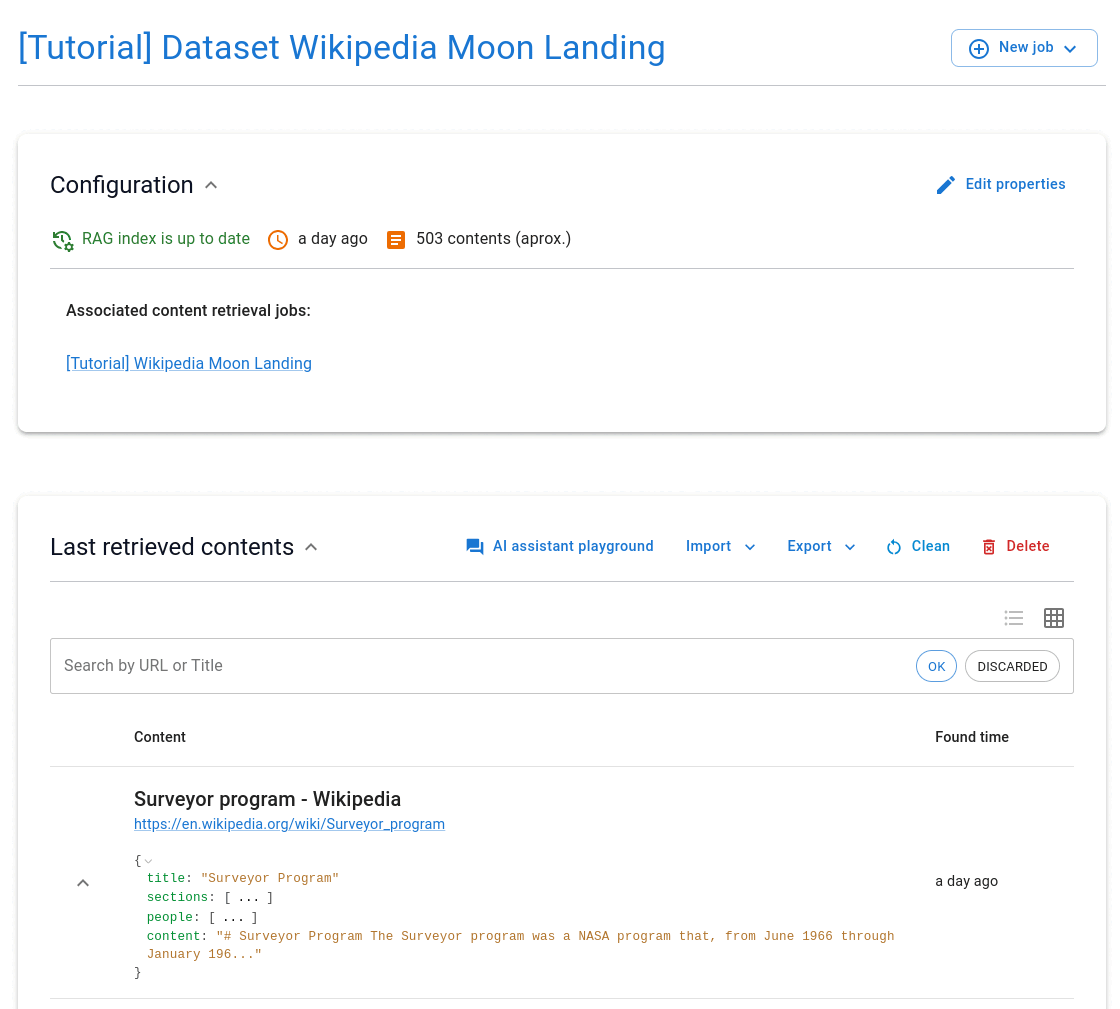
Configure and test your AI assistant
Next step is configuring the AI Assistant for this dataset. Content-driven AI assistants limit their replies to the content within the content datasets, and they will provide a reference about the source for each reply. This makes them much more reliable than generic-purpose assistants. There are numerous parameters you can set to change both the behaviour and the look & feel of the AI assistant. Among others:
- Bot name and description
- Avatar image
- Bot behaviour and instructions
- Query Hinting
- Style settings, colour and fonts
- Security aspects
All those settings will allow you to fully customize the experience and what kind of replies the assistant will be providing.
4
Embed the assistant in your own webpage
The final step, if you want to make it accessible outside of saas.kynerix.ai, is embedding the assistant into your HTML code. Just click on 'Integration' > 'Web Integration' and follow the steps. By copying the HTML snippets into your own website or application, your users will be able to start taking advantage of AI search and assistance with minimal effort.
Advanced crawler configuration options.
Getting the right information is key to make sure the AI search is accurate and useful. There are some advanced features that will help with this described below:
1
Crawler navigation control
You may want to force the crawler to limit itself to a given subset of pages. That will make the crawling more efficient, by preventing visiting pages that are not really required by your needs. You can use the URL include option, to use wildcard expressions to limit your crawler to some sections of your website. For example, "*/faqs/*, */documents/*". Similarly, use URL exclude to avoid indexing some paths or pages.
Use AI to follow links. That will use AI to perform a smart selection of the links to follow, based on a specified prompt. For example, you can state 'Only those links related to some product descriptions and documentation'.
2
Data Validation and Transformation rules
You may want to specify which contents you don't want to add to the AI assistant knowledge data sets, or simply transform them.
Validate contents with AI. This will allow the job to filter out pages based on the semantic of its content, or any other rule. The discarded contents will still be stored, but won't be use by the assistants.
Transform contents with AI. You can run a prompt to transform each page content. Typical use cases are summarization, filtering, transformation, and quite typically, generate a JSON representation of the content and its metadata. If you click Use Structured JSON Output you must specify the format of the JSON. Each page will turn into valid JSON.
3
Periodic job execution
You may want to specify which contents you don't want to add to the AI assistant knowledge data sets, or simply transform them.